
Wikipedia: “Waikato Environment for Knowledge Analysis (Weka), developed at the University of Waikato, New Zealand, is free software licensed under the GNU General Public License, and the companion software to the book “Data Mining: Practical Machine Learning Tools and Techniques“.
Weka contains a collection of visualization tools and algorithms for data analysis and predictive modeling, together with graphical user interfaces for easy access to these functions.
The original non-Java version of Weka was a Tcl/Tk front-end to (mostly third-party) modeling algorithms implemented in other programming languages, plus data preprocessing utilities in C, and a Makefile-based system for running machine learning experiments.
This original version was primarily designed as a tool for analyzing data from agricultural domains, but the more recent fully Java-based version (Weka 3), for which development started in 1997, is now used in many different application areas, in particular for educational purposes and research”
As the title of the article suggests, WEKA is a tool that will allow you to do Machine Learning without any programming language but using only the GUI of the tool.
In this article, we are going to show you how to launch WEKA, and how to start using it, what each of the components means, and help you decide if it is the right tool for your needs.
In the end, we are going to discuss if WEKA is going to change the traditional way of doing Machine Learning and is it sufficient enough to allow us to do Machine Learning without any programming language.
Before you start, you can download WEKA here, and start your journey of doing Machine Learning without any programming language.
How to use WEKA
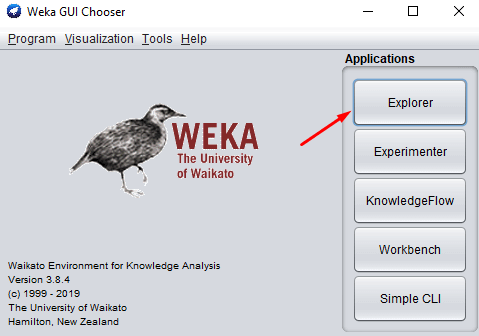
Image 1: Opening WEKA application
Once you’ve installed WEKA, you need to start the application. Once it starts you will get the window on Image 1. Click on the Explorer button as shown on the image.
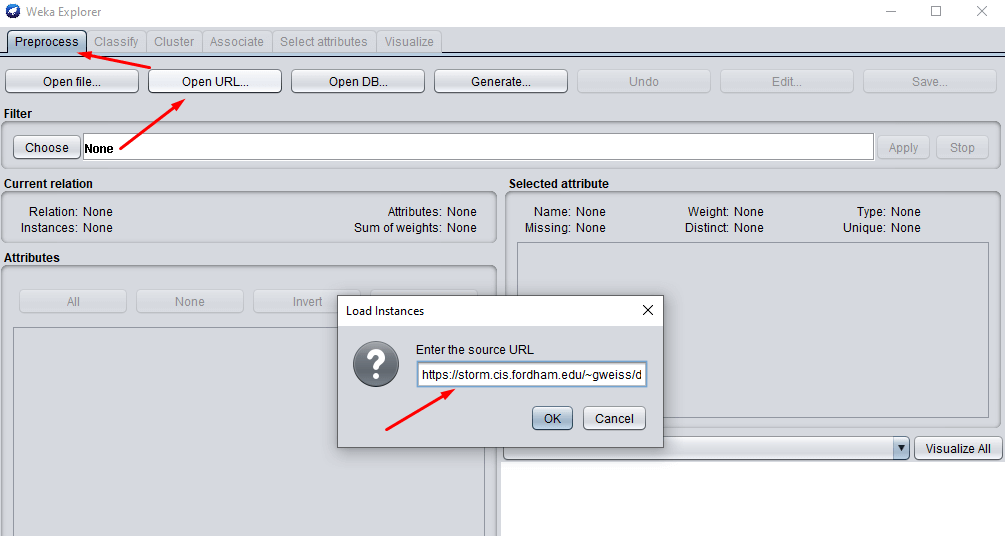
Image 2: Load data
The next thing to do is to load a dataset. Once you’ve clicked on the Explorer button, you will get the window showed in Image 2. In the Preprocess tab, you can choose different ways of loading data. In this article we are going to load it, using a URL.
The URL is the official WEKA dataset, and you can get it here.
If you do not want to open the link, here it is in its raw form: https://storm.cis.fordham.edu/~gweiss/data-mining/weka-data/weather.nominal.arff
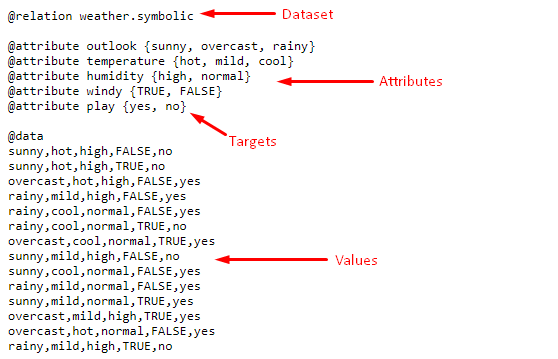
Image 3: Description of the dataset format
If you open the link to the dataset, this is what it looks like. On Image 3, you can see how it is formatted.
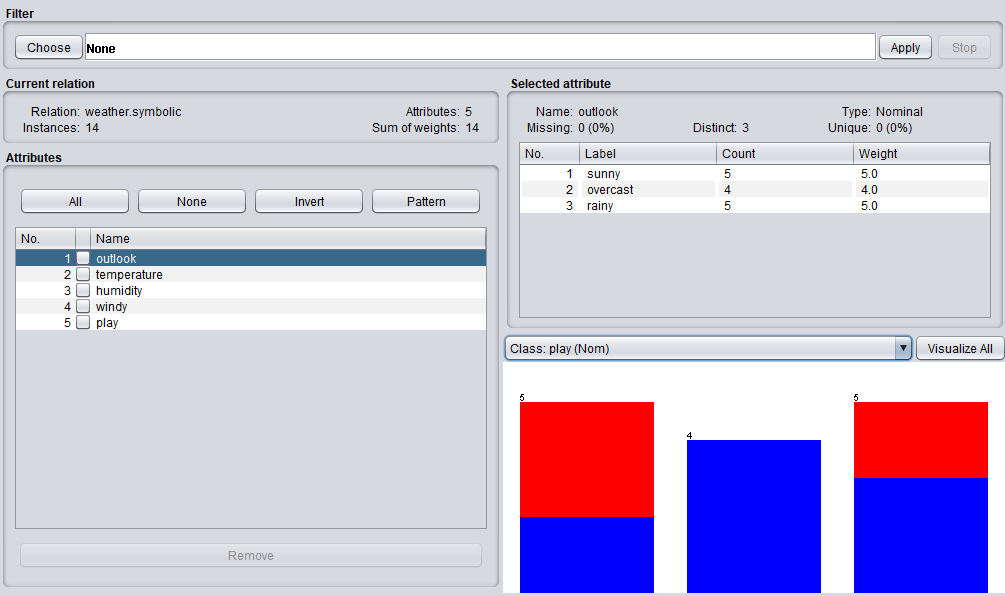
Image 5: The dataset is loaded in WEKA
After you’ve loaded the dataset, this is what you’ll get. In the Current relation, you can get the information that there are: 14 instances of data (14 rows of data as shown in the values section on Image 3), 5 attributes as shown in the Attributes section below.
You can click on any of the attributes and get more information in the Selected attributes section. In this instance, we’ve selected the outlook attribute.
As you can see on Image 4, or Image 5 (better) below, there is information about the name and the type of the attribute, the number of missing values, and a table with the nominal values for the selected attribute.
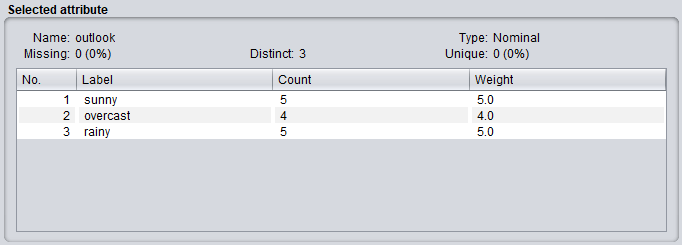
Image 5: Information for the selected attribute
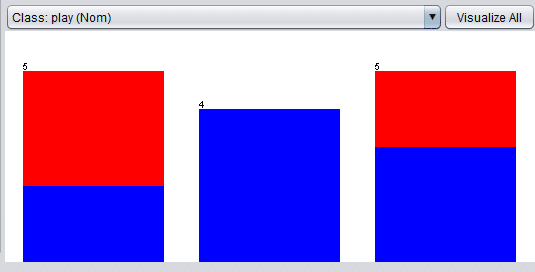
Image 6: Visualize classes based on the selected attributes
On Image 6, you can see the visualization of the classes based on the selected attributes. In this instance, we’ve selected the play class, which is our target, and you can see that based on the outlook values (paired with other attributes) you can get different outcomes, 3 NO and 2 YES if the outlook is sunny, 4 YES if the outlook is overcast, 2 NO and 3 YES if the outlook is rainy.
To support the visualization precision, we can take a look at Image 3, or Image 7 where we’ve explained detailly.
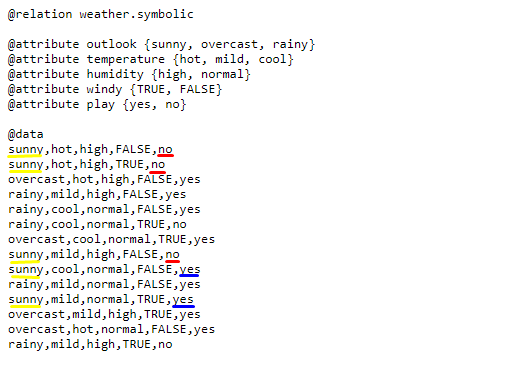
Image 7: Detailed visual explanation of the class outcome based on the attribute
Next, thing, we are going to do classification on our dataset.
To do that, we need to open the Classify tab, where we get the window shown on Image 8 below.
Image 8: The Classify window
The first thing that comes on our way is the Test option, where we have a choice of 4 options. This is what of those options you should use when you are using WEKA: If you have your own training set, you would use cross-validation or percentage split options.
Under cross-validation, you can set the number of folds in which entire data would be split and used during each iteration of training. In the percentage split, you will split the data between training and testing using the set split percentage.
The next thing we need to select the target, we are going to stick with the play attribute as our target.
Then we need to select the classifier.
We are going to use а decision tree structure to make the classification. We are going to use two different algorithms (RandomForest and J48), and then we are going to compare the results.
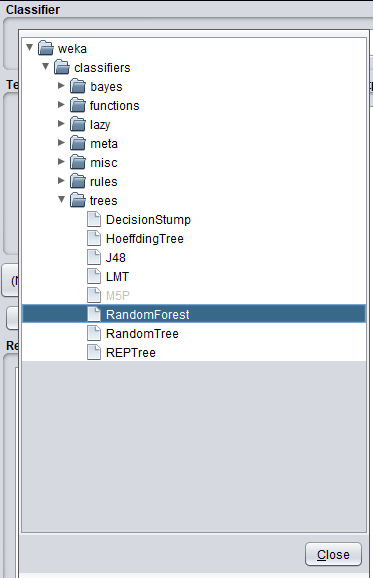
Image 9: Select RandomForest algorithm
After you’ve selected your classifier, you will click on the Start button.
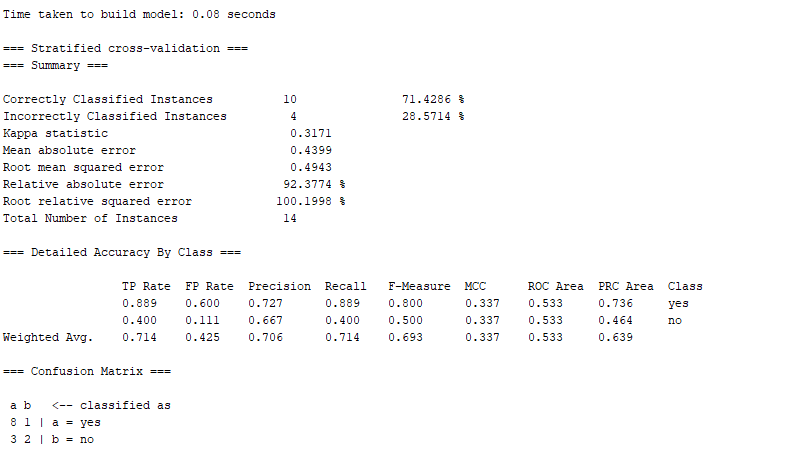
Image 10: Results from the classification using RandomForest algorithm
In Image 10, you can see the results we’ve got the results from the classification using the RandomForest algorithm.
There is information about the correctly classified instances 71.4286% and incorrectly classified instances 28.5714%, plus other statistical information, and in the end, there is a Confusion matrix.
Next, we are going to do the same with the J48 algorithm. J48 is an open-source Java implementation of the C4.5 algorithm for the needs of the WEKA tool since WEKA is written in Java.
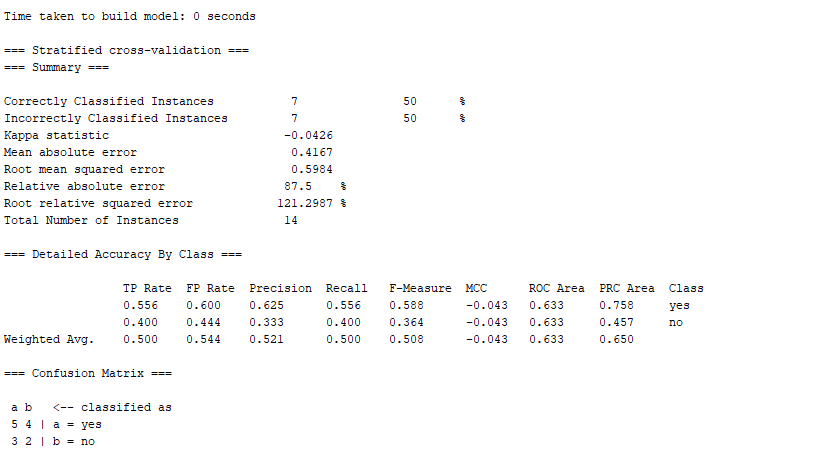
Image 11: Results from the classification using the J48 algorithm
On Image 11, you can see the same information as you’ve seen on Image 10, except for the J48 algorithm.
From the information, we can see that this algorithm is less precise than the RandomForest since it has only 50% correctly classified instances.
Since this is a tree and not a combination of trees (like RandomForest), we can visualize the results as a decision tree. If you don’t know how to do that, take a look at Image 12, below.
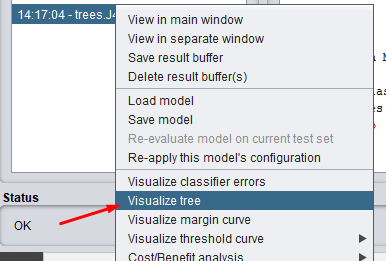
Image 12: Visualize the results as a decision tree
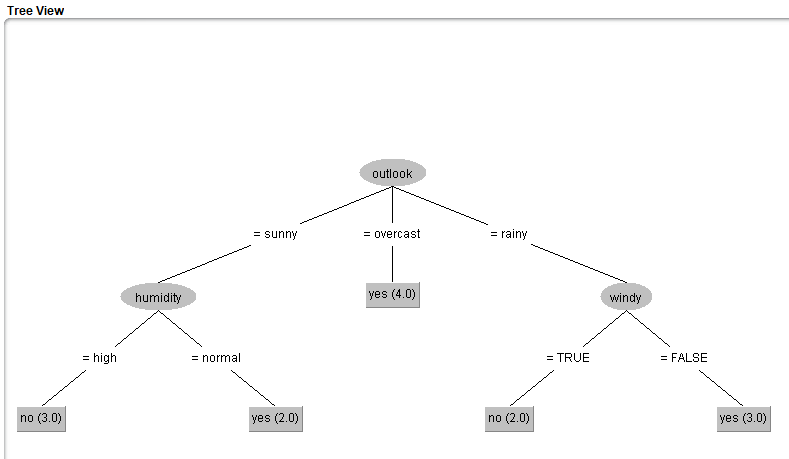
Image 13: Visualize tree
Conclusion
Now, the big question, is WEKA going to make Machine Learning easier by replacing the programming languages? No. No, it’s not going to do that. WEKA is great for beginners or people that do not have big programming experience.
WEKA is good to help you start with Machine Learning and understand the basics, but it is limited to smaller datasets, and to capabilities that its libraries and packages can do.
By using programming language, you have almost unlimited freedom of doing different customizations that will satisfy any of your project’s needs.
This being said, you shouldn’t stop learning because it is limited, it is still a great tool, that can save a lot of time, and finish a lot of work.
WEKA is showing us that in the future we might have a tool that can allow us to do cutting edge Machine Learning using only our GUIs, so it is a tool to keep an eye on.
Check our older articles below, you might find them helpful.
- FREE Computer Science Curriculum From The Best Universities and Companies In The World
- How To Become a Certified Data Scientist at Harvard University for FREE
- How to Gain a Computer Science Education from MIT University for FREE
- Top 50 FREE Artificial Intelligence, Computer Science, Engineering and Programming Courses from the Ivy League Universities
- Top 10 Best FREE Artificial Intelligence Courses from Harvard, MIT, and Stanford
- Top 10 Best Artificial Intelligence YouTube Channels in 2020
Like with every post we do, we encourage you to continue learning, trying, and creating.




