
Deep learning is part of machine learning methods based on artificial neural networks with representation learning.
Deep learning architectures such as deep neural networks, deep belief networks, recurrent neural networks, and convolutional neural networks have been applied to fields including computer vision, speech recognition, natural language processing, audio recognition, social network filtering, machine translation, where they have produced results comparable to and in some cases surpassing human expert performance.
We have tons of examples of how Deep Learning improved already pretty good algorithms, like AlphaGo, AlphaGo Master, AlphaGo Zero, AlphaZero, and many others.
You can find a lot of research papers on OpenAI and DeepMind related to Deep Learning in many fields, as well as how to tune certain hyper-parameters in order to produce better results.
Now, all of this is fine, but, is a Deep Learning solution to everything? Should we implement it in every situation, since it achieves superhuman precision?
In this article, we are going to reveal some reasons, why we shouldn’t use Deep Learning.
Most popular books you should read about Deep Learning:
Deep Learning with Python –Buy from Amazon

Deep Learning from Scratch: Building with Python from First Principles – Buy from Amazon

5 situations where you shouldn’t use Deep Learning
Easy to solve problems

It is really cool when you can say that you created a Deep Learning model that produces high-quality output, but first, you should try to determine the complexity of your problem.
The best solution is not the one that uses the most popular and the hardest to implement techniques, but the one that produces output on the most optimal way in a sense of resources used and time spend to implement it.
If you have problems, where you can produce a solution in an easier way than using Deep Learning, than do that. It will save you time, CPU resources and it will be easier for others to understand it.
Low budget

We’ve already said that Deep Learning requires high computational power. Most of the complex problems are actually executed on the GPU, so in order to do that, you need some powerful GPU that can be quite expensive.
Now, of course, there are cheaper and free solutions, like Google Colab or Clarifai. But if you want to create something pretty custom it is going to cost a lot, because you are going to need to buy your own GPU and create the right infrastructure to help you run it, or you will need to subscribe to some of the mentioned services, and that can also be pretty expensive.
Small datasets
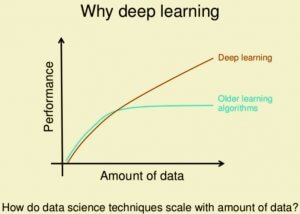
From the image, we can see that Deep Learning performance is better than the other older algorithms as the size of the data is growing. We don’t say that it will not perform well with small data, but if the data is bigger it achieves higher performance.
Examples for this are the COCO dataset and ImageNet dataset that contains hundreds of thousands and millions of samples respectively.
So if you use a small dataset try to solve the problem using some other simpler techniques and just compare the results. If the results are close than just use the simpler technique.
If the useful learning features are already extracted from the data

When you want to create a Machine Learning model, you need to label the data (supervised learning) or let the model label it, itself (unsupervised learning).
Now this means that you need to extract the useful features from the dataset that will help the model learn. If you can determine yourself (or by using some easy technique) then don’t use Deep Learning.
You don’t need to complicate everything (as we’ve said in the earlier sections), take those features and ingest it to your simpler model.
The Deep Neural Networks are “black boxes”

Deep networks are very “black box” in that even now researchers do not fully understand the “inside” of deep networks. They have high predictive power but low interoperability.
Hyper-parameters and network design are also quite a challenge due to the lacking theoretical foundation.
On the other hand, classical ML algorithms such as regression or random forests are quite easy to interpret and understand due to the direct feature engineering involved.
In addition, tuning hyper-parameters and altering the model designs is more straightforward since we have a more thorough understanding of the data and underlying algorithms.
These are particularly important when the results of the network have to be translated and delivered to the public or a non-technical audience.
Conclusion
Deep Learning is cutting edge technology, it is pretty powerful and keeps improving all of our creations. With its power comes its price and requirements that must be managed in the right way in order to avoid the problems that we’ve mentioned in the previous section.
If you want to learn more about Deep Learning we suggest you take a look at our articles about getting started with Artificial Neural Networks and Explanation of Keras for Deep Learning and Using It in Real-World Problem.
With the current COVID-19 situation we’ve made an article about using Deep Learning in the fight against COVID-19 which is named How To Predict Coronavirus (COVID-19) Cases Using Deep Learning in Python.
Also if you want to take a part in the fight against the Coronavirus (COVID-19) using Artificial Intelligence take a look at our articles about Predicting the Number of Infected People by the Coronavirus with Python Code, Forecasting the Spread of Coronavirus (COVID-19) Using Python and This Is How Python Can Defeat The Coronavirus (COVID-19).
Like with every post we do, we encourage you to continue learning, trying and creating.



